使用JADX-MCP高效反混淆
概述
通过优化提示词,规范化agent的行为,从而得到一套高效率的java层反名称混淆方法
痛点
在安卓逆向过程中,我们常遇到这样的混淆
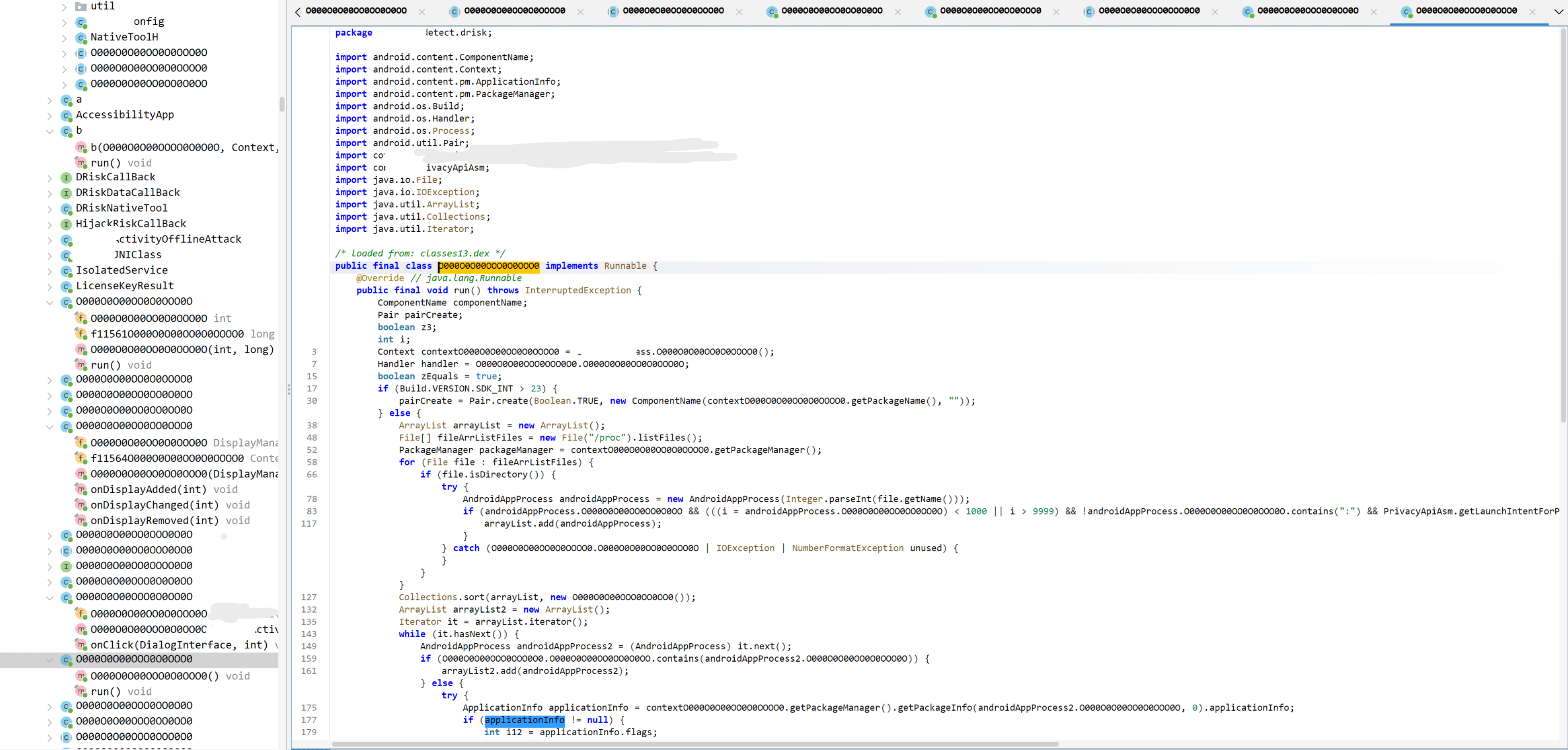
总结起来可以分几类:
1、unicode小语种类,比如阿拉伯语,类名竟然能竖起来。(可以用插件转变为类似第三种)
2、O0o、1lI、ILZ类
3、短字符类,比如f0、a、ab
对于只有名称混淆的,我们可以使用jadx-mcp配合ai根据语义快速且高效地批量进行恢复,从而把逆向工程周期极大地缩短。
思路
实测JEB-MCP占资源太大,而且过于卡,反编译一个类可能需要几分钟,对于我这种计算资源比较少的小牛马显然JEB还是过于笨重了。不过之前的提示词还是有效的,可以考虑把提示词迁移至jadx-mcp。于是找到了https://github.com/zinja-coder/jadx-ai-mcp这个项目。
jadx-mcp部署和连接
jadx-mcp实际上是两部分,分别是JADX-AI-MCP和JADX-MCP-SERVER,前者是一个jar,是jadx插件,后者是标准的mcp服务器。
我的IDE是google的antigravity,官方没有提供安装方法,不过这个IDE一看就是vscode改过来的,所以可以参考roocode、cline这种进行配置。此处有一个坑点:我为antigravity配置了socks5代理,导致JADX-MCP-SERVER网络连通性测试出现异常。解决方案是下面配置中的env字段。注意timeout设大一点。
修改~\.gemini\antigravity\mcp_config.json,添加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| {
"mcpServers": {
"jadx-mcp-server": {
"command": "uv",
"args": [
"--directory",
"d:/xxxxx/jadxmcp",
"run",
"jadx_mcp_server.py"
],
"env": {
"HTTP_PROXY": "",
"HTTPS_PROXY": "",
"ALL_PROXY": "",
"NO_PROXY": "*"
},
"timeout": 1800
}
}
}
|
连接好之后,在manage mcp servers界面,应该能出来可用的mcp函数列表,整理如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| # 核心代码获取与导航
fetch_current_class 获取 JADX-GUI 插件中当前选中的类及其代码。
get_selected_text 返回反编译代码视图中当前选中的文本。
get_method_by_name 根据名称获取特定类中方法的源代码。
get_all_classes 返回项目中的所有类列表(支持分页)。
get_class_source 获取特定类的 Java 源代码。
search_method_by_name 在所有类中搜索特定的方法名。
get_methods_of_class 列出一个类中的所有方法名称。
search_classes_by_keyword 搜索源代码中包含特定关键字的类。
get_fields_of_class 列出一个类中的所有字段名称。
get_smali_of_class 获取一个类的 Smali 代码表示。
# 资源与清单文件
get_android_manifest 获取并返回 AndroidManifest.xml 的内容。
get_strings 获取 strings.xml 文件的内容。
get_all_resource_file_names 获取所有资源文件的名称。
get_resource_file 获取特定资源文件的内容。
get_main_application_classes_names 从 Manifest 包配置中获取主应用程序(Application)类的名称。
get_main_application_classes_code 获取主应用程序(Application)类的代码(支持分页)。
get_main_activity_class 从 AndroidManifest.xml 中获取主 Activity 类。
# 重构与重命名
rename_class 重命名特定的类。
rename_method 重命名特定的方法。
rename_field 重命名特定的字段。
rename_package 重命名一个包及其包含的所有类。
# 调试 (Debug)
debug_get_stack_frames 获取当前的栈帧(调用栈)。
debug_get_threads 获取被调试进程中的所有线程。
debug_get_variables 在进程挂起(暂停)时获取当前变量。
# 交叉引用 (Xrefs)
get_xrefs_to_class 查找对某个类的所有引用。
get_xrefs_to_method 查找对某个方法的所有引用。
get_xrefs_to_field 查找对某个字段的所有引用。
|
提示词设计和优化
之前flanker发布的JEB-MCP中的提示词如下:
1
2
3
4
5
| 1. 连接MCP jadx-mcp-server
2. 分析D:\xxx.apk应用的com.xxx.MainActivity类的功能
3. 根据功能重命名所有方法名小于3个字符的名称
4. 如果调用了其他类的方法,分析相应的类功能,并重命名方法名小于3个字符的名称
5. 输出分析过程。
|
经过测试我的智障AI+MCP无法达到演示的效果。此种情况,可以将大的长期目标(完成反混淆)拆分成多个小的短期目标(获取类的代码,分析功能,重命名包、类、字段、方法的名称等等)。我们将需求告诉贵的、聪明的AI,让AI来拆分任务、形成一个初步提示词。然后我们把需要改善的地方告诉他,让他来优化。最后我们拿这个优化好的提示词去让便宜的、笨的AI去大量地做,以节省token和提高速度。
优化后的提示词如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| # Role Definition
You are an advanced Android Reverse Engineering Expert Agent driven by JADX MCP. You excel at static code analysis in highly adversarial, heavily obfuscated environments. Your core principle is "evidence-based reasoning"—never guess.
# Task Context
* **Target APK Path:** `xxx.apk`
* **Target Scope:**
* *Mode A (Entry Class):* `com.xxxxx.XXX`
* *Mode B (Package Scan):* `[User provided package name]`
* **Output File:** `rename.txt`
* **Format Standard:** Defined in file `rename_templete.txt`
# Execution Workflow
## Phase 1: Scope Definition
1. Connect to JADX MCP.
2. Check user input:
* If **Package Name**: Call `search_classes_by_keyword` to get the class list, and output "Scanning package [Package Name], found [N] classes".
* If **Class Name**: Lock onto that class directly.
## Phase 2: Deep Analysis & Adversarial Detection
Iterate through every class in the target list (CurrentClass) and execute the following strict steps:
1. **Source Retrieval:** Get source code.
2. **Adversarial Environment Check (Critical):**
Before starting logic analysis, scan for situations JADX cannot handle and **record alerts immediately**:
* **Native Methods:** Are there methods modified by the `native` keyword? (C++ implementation cannot be analyzed)
* **Phantom Calls:** Are there calls to non-existent classes or methods? (Likely dynamic loading or class stripping)
* **Empty Methods:** Is the body of a called method empty? (Likely removed by obfuscator or instrumentation trap)
* *Action:* If found, explicitly mark in the analysis brief as "Unable to analyze: [Reason]".
3. **Deobfuscation Logic:**
For identifiers matching obfuscation characteristics (length < 3, meaningless characters), search for "Semantic Anchors" (strings, APIs, return values).
* **Strict Rule:** If no concrete evidence is found (such as explicit strings or API calls), or the logic is too obscure, you **must** rename it to `Unknown` or `Unknown_Method_[Hash]`. **Absolutely do not force meaning.**
## Phase 3: Recursive Dependency Analysis (Strict Control)
To understand the full context of the current class, check its external dependencies, but you must adhere to the following **circuit breaker mechanism**:
1. **Dependency Scan:** Scan all external classes/methods called by the current class.
2. **Filter Condition (Recursion Admission):** Initiate recursive analysis on an external class only if **all** the following conditions are met:
* The external class **is also obfuscated** (matches Phase 2 obfuscation characteristics).
* The external class has **not** been analyzed yet (Idempotency Check).
* **Recursion Depth:** Current recursion depth < **5 levels** (Depth < 5).
3. **Stop Check:** Once the depth limit is reached, stop tracing and mark it as `External_Obfuscated_Ref` at the current level to prevent Context Explosion.
## Phase 4: Progress Reporting
**Upon completing the analysis of a class (and its recursive dependencies), you must output a short report to the user:**
> "Analyzed Class: [ClassName] (Recursion Depth: [N]). Found [N] obfuscation points, Renamed [M], Unknown [X]. Adversarial Warning: [None/Native/Phantom]"
## Phase 5: Final Output Generation
Read and compile all renaming records, strictly following the format in `rename_templete.txt` to output to the file `rename.txt`.
|
rename_templete.txt内容如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| # rename.txt 规范说明
# =====================
# 格式: [类型]|[包名/类名]|[原名]|[新名]|[功能说明]
# 类型: C=类, M=方法, F=字段
# 每行一条记录,便于追加和快速解析
# 新会话时只需读取最后N行即可恢复上下文
#
# 示例:
# C|com.xxxxx|O000O0O00OOO0OOO0O0|HijackDetectionManager|劫持检测管理器
# M|com.xxxxx.HijackDetectionManager|O000O0O00OO0O0OOO0O|handleActivityPaused|Activity暂停处理
# F|com.xxxxx.HijackDetectionManager|O000O0O00OO0O0OOO0O|sMainHandler|主线程Handler
=================================================================
XXX 包反混淆记录
=================================================================
# 类重命名
C|com.xxxxx|O000O0O00OO0O0OOO0O|SamplingMonitorRunnable|原生采样监控Runnable
C|com.xxxxx|O000O0O00OO0O0OOOO0|HijackActivityLifecycleCallback|劫持检测Activity生命周期回调
# 方法重命名
M|com.xxxxx.unexp.AttackResponseHandler|O000O0O00OO0O0OOO0O|handleAttackDetected|处理检测到的攻击
M|com.xxxxx.xxxxxx|O000O0O00OO0O0OOO0O|onHomeKeyPressed|Home键按下回调
M|com.xxxxx.xxxxxx|O000O0O00OO0O0OOOO0|getContext|获取Context
# 字段重命名
F|com.xxxxx.xxxxxx|O000O0O00OO0O0OOO0O|sContext|上下文
F|com.xxxxx.HijackDetectionManager|O000O0O00OO0O0OOO0O|sMainHandler|主线程Handler
F|com.xxxxx.HijackDetectionManager|f11565O000O0O00OO0O0OOOO0|sCurrentComponent|当前组件
|
核心思想
1、强调“递归”,这样我们能让AI从我们更感兴趣的点或面入手,扩散至与他们相关的部分。这样能避免大量分析一些标准的、框架性质的、不是很感兴趣的功能。
2、为什么不用mcp的get_all_classes这个功能?因为这个返回的是整个apk的class,支持分页是每页显示多少条那种,而不是显示某个包下的所有class,测试app有200000个类,每次100条,就需要调2000次,这样上下文会很容易撑爆,触发上下文压缩,这样AI就有可能忘掉前面的但是重要的东西。但是可以用search_classes_by_keyword这个功能,搜索结果会比较精准。
也许可以先全量跑一次生成一棵树,然后根据节点序号去查找?后续可能考虑从这里下手优化。
3、为什么要设计一个rename_templete.txt?输出类的命令,如果是简单的说“完成后将xxx输出”,AI会每次设计一个新的格式输出,这样太乱,也不方便后续可能的其他自动化操作。另外,上述格式可以让AI每次都追加,而不是全量读取或输出一遍。以后遇到诸如内存爆了、jadx白屏了这种问题,在重启后可以直接让mcp“重新执行最后x条重命名操作”,快速恢复进度。
效果
上面图片中的混淆示例,经过反混淆实际可以达到如下效果。
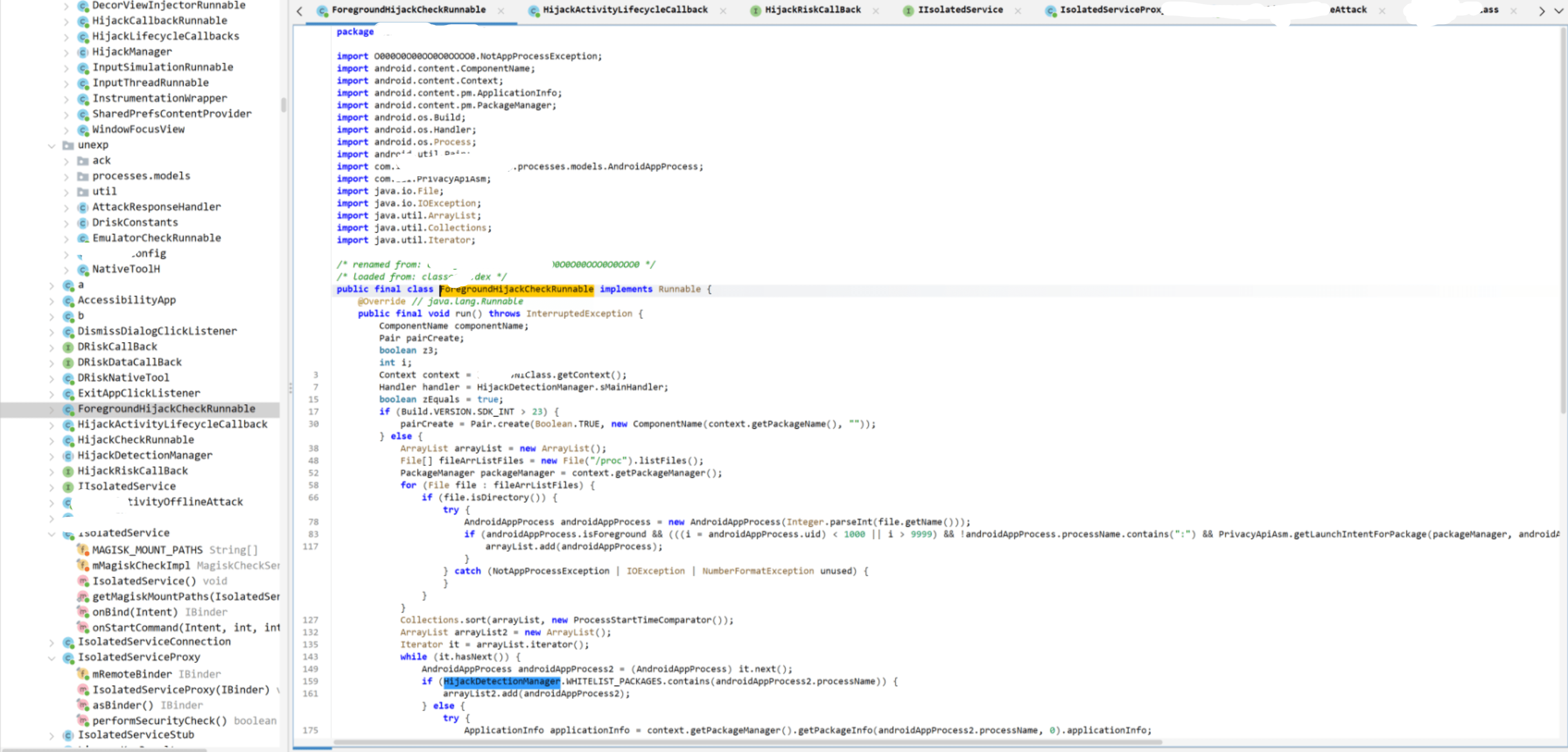
虽然还有一些错,但是基本上能看了。
